
Project information
- Scope:
Data scraping, Data mining, Database structuring, Text embedding vector generation, Prompt engineering, Retrieval-augmented generation (RAG) - Technologies:
Python, Pandas, Selenium, LangChain, FAISS, ChromaDB, ChatGPT, Streamlit - Demo video link: PubMedGPT
- WebApp link: Coming Soon
Accelerating research by leveraging the potential of Large Language Models
The challenge
Navigating the ever-expanding landscape of scientific literature poses considerable challenges for conducting comprehensive scientific reviews and sourcing clinical evidence. Sorting through this extensive corpus of literature demands significant time and effort, often resulting in information overload and potential oversight of crucial findings. Moreover, variations in publication quality, conflicting study outcomes, and the proliferation of predatory journals further complicate the process of discerning credible clinical evidence, emphasizing the pressing need for efficient and reliable tools to streamline this information retrieval process.
The solution
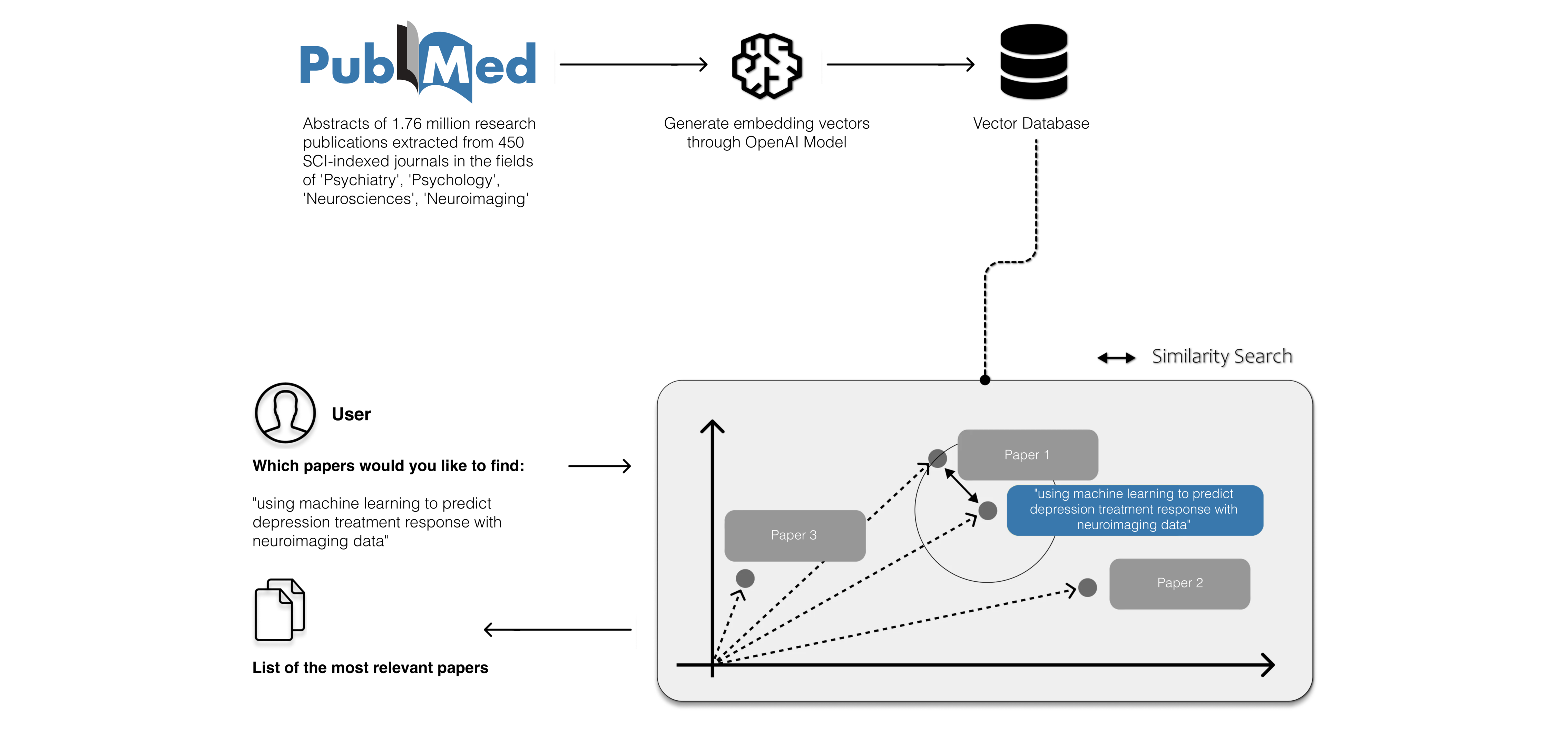
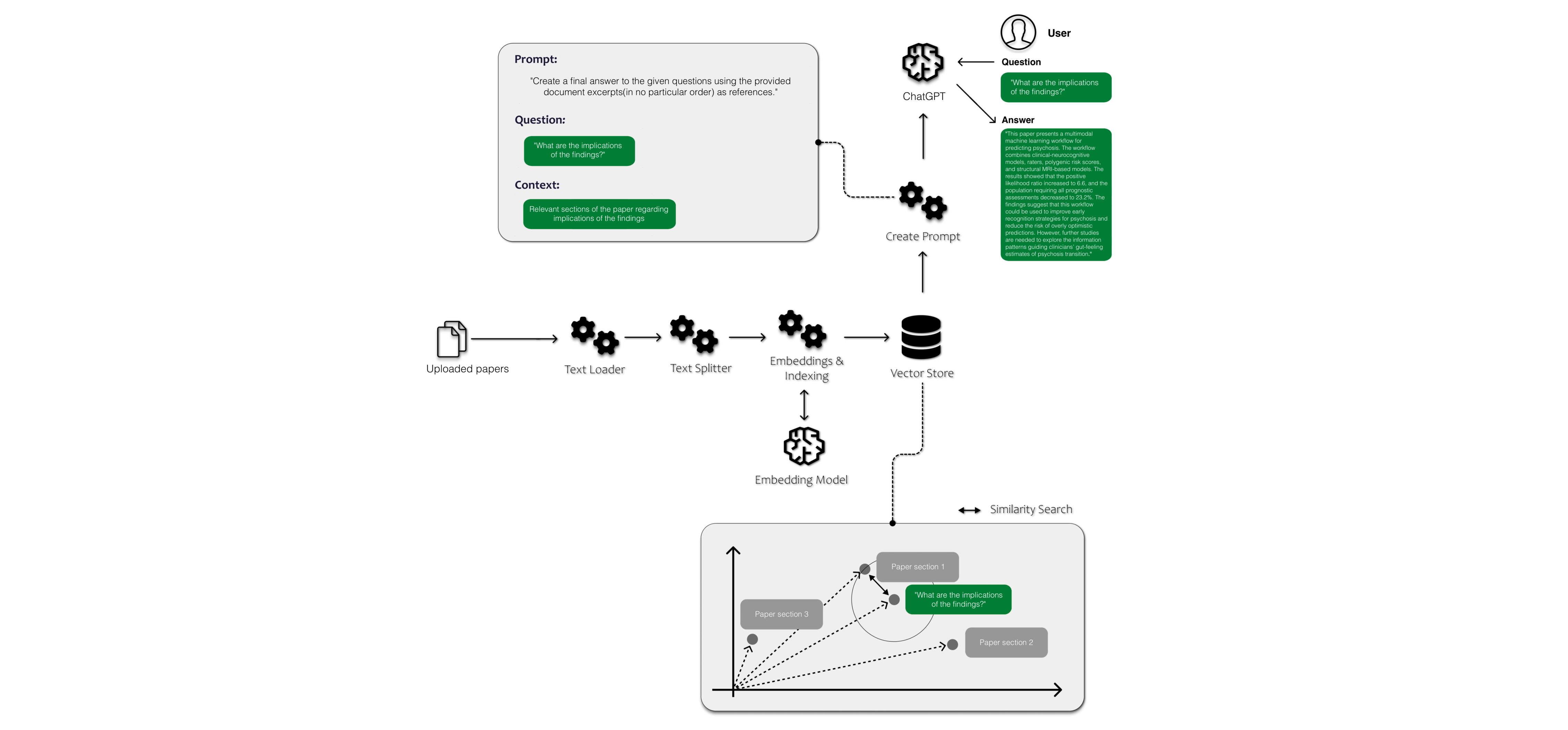
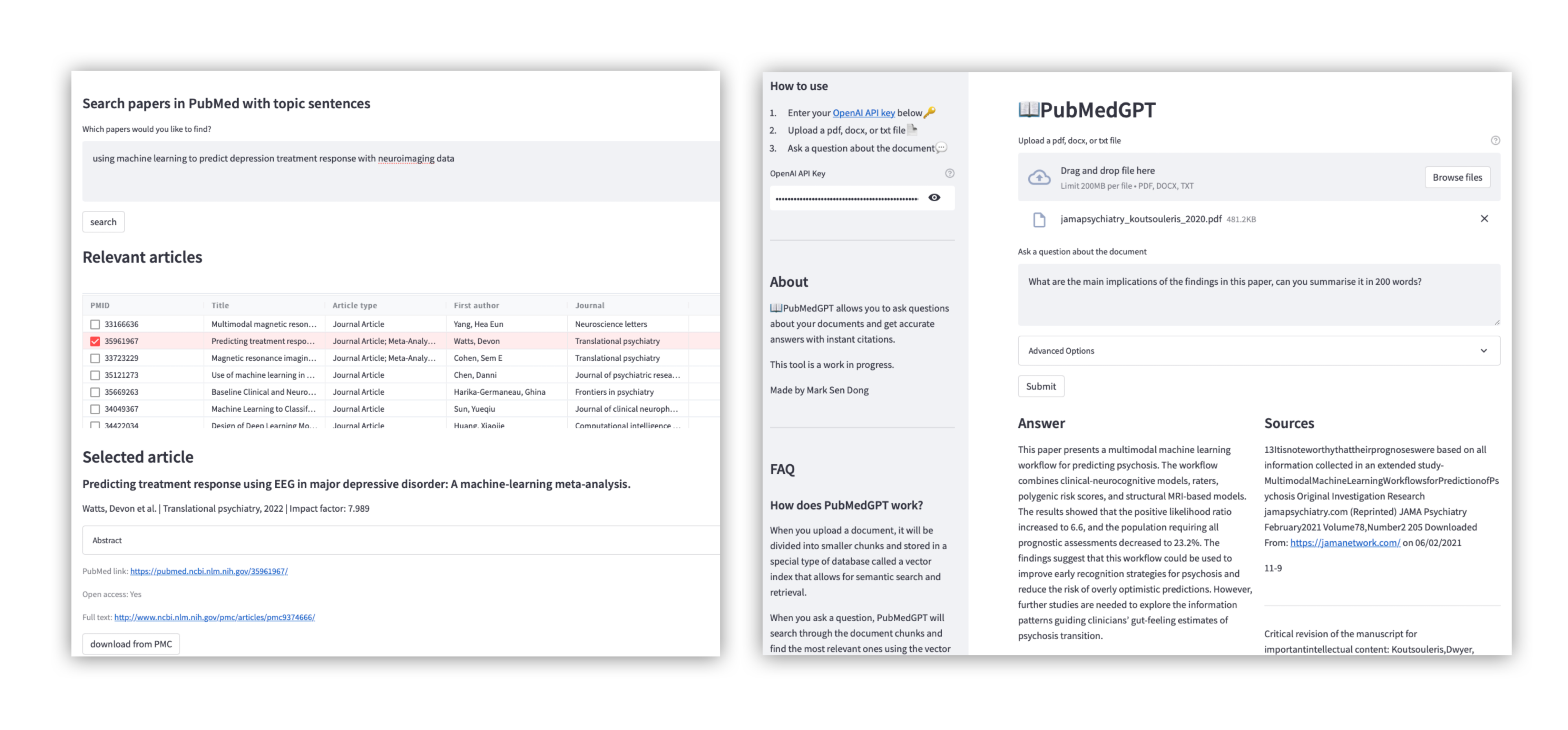
To help accelerate the research process, we created PubMedGPT. It is a ChatGPT-powered tool for precision paper search based on abstract content as well as a paper content retrieval chat-bot with Retrieval-augmented generation (RAG). PubMedGPT aims to enhance our efficiency and accuracy in reading and referencing scientific papers.
The end result
PubMedGPT incorporates two distinct pipelines to fulfill its main objectives. Firstly, we constructed a search engine utilising embedded abstracts from research papers sourced from the PubMed database. By employing text embedding, which converts text into numerical vectors, we enable efficient analysis by capturing semantic relationships and contextual similarities. This pipeline empowers users to conduct precision searches using naturalistic sentences instead of keywords. Secondly, we have developed a chat-bot using Retrieval-augmented generation that leverages the content of uploaded papers to answer questions. This pipeline allows users to swiftly access the most interesting and pertinent details without the need to read through the entire paper.